Consumer
Consumers are clients that read data from Kafka topics. They subscribe to one or more topics and process the data. Each consumer keeps track of its position in each partition using partition offset.
Kafka consumers follow a pull model. This means that consumers actively request data from Kafka brokers rather than having the brokers push data to them
Advantages of the Pull Model
A group of consumers work together to consume data from a topic. Each consumer in the group processes data from different partitions, allowing for parallel processing and load balancing.
Kafka consumers are typically part of a consumer group. When multiple consumers are subscribed to a topic and are part of the same group, each consumer will receive messages from a different subset of the partitions in the topic.
Here are some key points about consumer groups:
The offsets for each partition are stored in the __consumer_offsets topic on the Kafka broker. This allows Consumer to resume reading from the correct position in case of a restart or failure.
Example #1: A single consumer group with one consumer and three partitions in Topic A
Consider a Kafka topic, Topic A, which is divided into three partitions: Partition 0, Partition 1, and Partition 2. You also have a consumer group, Consumer Group 1, with only one consumer, Consumer 1. Since there is only one consumer in the group, Consumer 1 will be assigned all three partitions of Topic A. This means Consumer 1 will read messages from Partition 0, Partition 1, and Partition 2.
Since there is only one consumer in the group, Consumer 1 will be assigned all three partitions of Topic A. This means Consumer 1 will read messages from Partition 0, Partition 1, and Partition 2.
Disadvantage
Example #2: A single consumer group with two consumers and three partitions in Topic A
Consider a Kafka topic, Topic A, which is divided into three partitions: Partition 0, Partition 1, and Partition 2. You also have a consumer group, Consumer Group 1, with two consumers, Consumer 1 and Consumer 2.
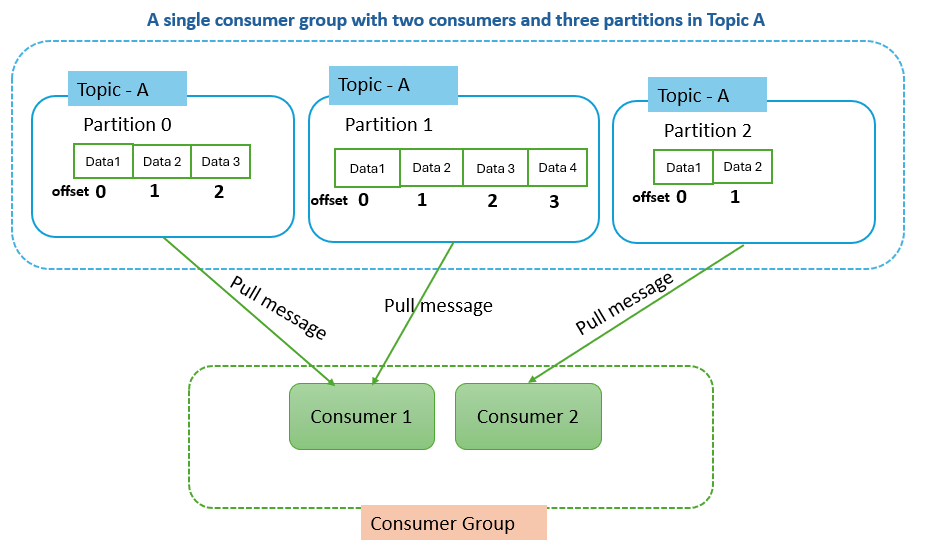
Since there are three partitions and two consumers, one consumer will be assigned two partitions, and the other consumer will be assigned one partition. It means Consumer 1 might be assigned Partition 0 and Partition 1, while Consumer 2 is assigned Partition 2.
Advantages
Example #3: A single consumer group with three consumers and three partitions in Topic A
Consider a Kafka topic, Topic A, which is divided into three partitions: Partition 0, Partition 1, and Partition 2. You also have a consumer group, Consumer Group 1, with three consumers, Consumer 1, Consumer 2 and Consumer 3.
 Since there are three partitions and three consumers, each consumer will be assigned exactly one partition. It means Consumer 1 might be assigned Partition 0, Consumer 2 might be assigned Partition 1 and Consumer 3 might be assigned Partition 2
Since there are three partitions and three consumers, each consumer will be assigned exactly one partition. It means Consumer 1 might be assigned Partition 0, Consumer 2 might be assigned Partition 1 and Consumer 3 might be assigned Partition 2
Advantages
Example #4: A single consumer group with four consumers and three partitions in Topic A
 Since there are three partitions and four consumers, one consumer will not be assigned any partition. It means Consumer 1 might be assigned Partition 0, Consumer 2 might be assigned Partition 1, Consumer 3 might be assigned Partition 2 and Consumer 4 will not be assigned any partition and will remain idle until a rebalance occurs.
Since there are three partitions and four consumers, one consumer will not be assigned any partition. It means Consumer 1 might be assigned Partition 0, Consumer 2 might be assigned Partition 1, Consumer 3 might be assigned Partition 2 and Consumer 4 will not be assigned any partition and will remain idle until a rebalance occurs.
Advantages
Disadvantage
When you have multiple applications that need to process the same data differently, you can create separate consumer groups for each application. Each group will independently consume the messages and apply its own processing logic.
If one consumer group fails or lags behind, it does not affect the other groups

Message Delivery Semantics
Kafka provides three main message delivery semantics to ensure different levels of reliability and performance
Happy Coding :)
Consumers are clients that read data from Kafka topics. They subscribe to one or more topics and process the data. Each consumer keeps track of its position in each partition using partition offset.
Kafka consumers follow a pull model. This means that consumers actively request data from Kafka brokers rather than having the brokers push data to them
Advantages of the Pull Model
- Consumers can control the rate at which they consume messages, allowing them to manage varying loads more effectively.
- Consumers have the capability to retrieve messages in batches, enhancing both network and processing efficiency.
- If a consumer runs into an error, it can attempt to fetch the messages again without impacting other consumers.
A group of consumers work together to consume data from a topic. Each consumer in the group processes data from different partitions, allowing for parallel processing and load balancing.
Kafka consumers are typically part of a consumer group. When multiple consumers are subscribed to a topic and are part of the same group, each consumer will receive messages from a different subset of the partitions in the topic.
Here are some key points about consumer groups:
- Each partition of a topic is allocated to a single consumer within a group at any given time. This guarantees that each message is handled by only one consumer in the group.
- Consumer groups enable horizontal scaling. By adding more consumers to a group, Kafka will redistribute the partitions among the consumers, leading to more efficient data processing.
- If a consumer in a group fails, Kafka will automatically rebalance the partitions assigned to that consumer among the remaining consumers in the group.
The offsets for each partition are stored in the __consumer_offsets topic on the Kafka broker. This allows Consumer to resume reading from the correct position in case of a restart or failure.
Example #1: A single consumer group with one consumer and three partitions in Topic A
Consider a Kafka topic, Topic A, which is divided into three partitions: Partition 0, Partition 1, and Partition 2. You also have a consumer group, Consumer Group 1, with only one consumer, Consumer 1.

Disadvantage
- With just one consumer, there is no parallel processing of partitions. The single consumer handles all partitions, which could become a bottleneck if the message volume is high.
Example #2: A single consumer group with two consumers and three partitions in Topic A
Consider a Kafka topic, Topic A, which is divided into three partitions: Partition 0, Partition 1, and Partition 2. You also have a consumer group, Consumer Group 1, with two consumers, Consumer 1 and Consumer 2.
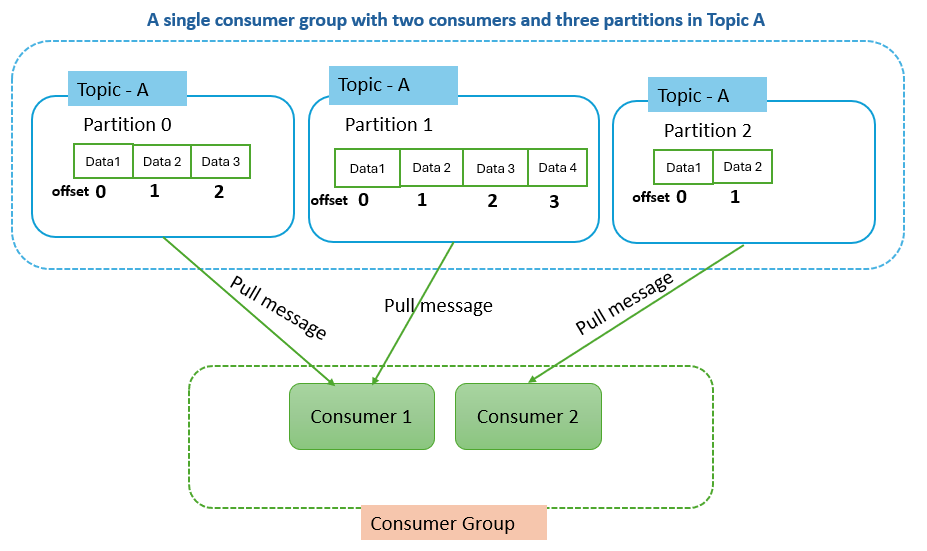
Since there are three partitions and two consumers, one consumer will be assigned two partitions, and the other consumer will be assigned one partition. It means Consumer 1 might be assigned Partition 0 and Partition 1, while Consumer 2 is assigned Partition 2.
Advantages
- With two consumers, the partitions are processed in parallel, improving the overall throughput and efficiency of message consumption
- The workload is shared among the consumers. However, because there is an odd number of partitions, one consumer will end up managing more partitions than the other.
Consider a Kafka topic, Topic A, which is divided into three partitions: Partition 0, Partition 1, and Partition 2. You also have a consumer group, Consumer Group 1, with three consumers, Consumer 1, Consumer 2 and Consumer 3.

Advantages
- With three consumers, the partitions are processed in parallel, maximizing the throughput and efficiency of message consumption.
- The load is evenly distributed among the consumers, with each consumer handling one partition.
Example #4: A single consumer group with four consumers and three partitions in Topic A
Consider a Kafka topic, Topic A, which is divided into three partitions: Partition 0, Partition 1, and Partition 2. You also have a consumer group, Consumer Group 1, with four consumers, Consumer 1, Consumer 2, Consumer 3 and Consumer 4.

- With three consumers, the partitions are processed in parallel, maximizing the throughput and efficiency of message consumption.
- The load is evenly distributed among the consumers, with each consumer handling one partition.
Disadvantage
- One consumer will remain idle as there are more consumers than partitions. This consumer will be available to take over if another consumer fails or if more partitions are added.
When you have multiple applications that need to process the same data differently, you can create separate consumer groups for each application. Each group will independently consume the messages and apply its own processing logic.
If one consumer group fails or lags behind, it does not affect the other groups

Message Delivery Semantics
Kafka provides three main message delivery semantics to ensure different levels of reliability and performance
- At Most Once: Messages are delivered once, and if there is a failure, they may be lost and not redelivered. This approach is suitable for scenarios where occasional data loss is acceptable and low latency is crucial.
- enable.auto.commit=true // configuration
- At Least Once: Messages are delivered one or more times, and if a failure occurs, messages are not lost but may be delivered more than once. This approach is suitable for scenarios where data loss is unacceptable, and duplicates can be handled.
- enable.auto.commit=false // configurationConsumer should commit offsets after processing messages to ensure they are not lost.
- Exactly Once: Messages are delivered exactly once, even in the case of retries. This ensures no duplicates and maintains message order. This approach is suitable for scenarios application requires strict data consistency and no duplicates.
- isolation.level=read_committed // configuration
Apache Kafka for Developers Journey:
- Apache Kafka for Developers #1: Introduction to Kafka and Comparison with RabbitMQ
- Apache Kafka for Developers #2: Kafka Architecture and Components
- Apache Kafka for Developers #3: Kafka Topic Replication
- Apache Kafka for Developers #4: Kafka Producer and Acknowledgements
- Apache Kafka for Developers #5: Kafka Consumer and Consumer Group
- Apache Kafka for Developers #6: Kafka Consumer Partition Rebalancing
- Apache Kafka for Developers #7: Kafka Consumer Commit Offset
- Apache Kafka for Developers #8: Kafka Consumer Auto Offset Reset
- Apache Kafka for Developers #9: Replacing ZooKeeper with KRaft
- Apache Kafka for Developers #10:Setting Up Kafka Locally with Docker
- Apache Kafka for Developers #11: Creating and Managing Kafka Topics
- Apache Kafka for Developers #12: Setting Up a Kafka Producer in Node.js using KafkaJS
- Apache Kafka for Developers #13: Setting Up a Kafka Consumer in Node.js using KafkaJS
- Apache Kafka for Developers #14: Order Processing with Kafka, Node.js Microservices, and MySQL
Comments
Post a Comment