Apache Kafka's architecture is designed to handle high-throughput, real-time data streams efficiently and at scale. Here are the key components:
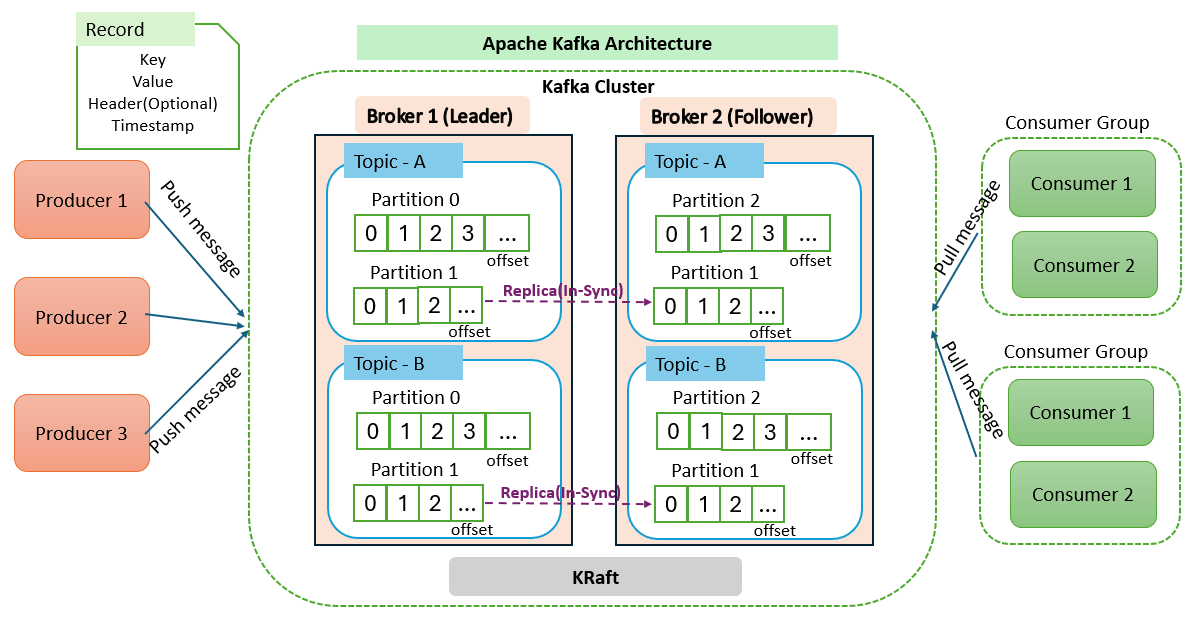
Kafka operates as a cluster composed of one or more servers, known as brokers. These brokers are responsible for storing data and handling client requests. Each broker has a unique ID and can manage hundreds of thousands of read and write operations per second from thousands of clients.
Topic
A topic is a category where records are stored in the Kafka cluster. Topics are divided into multiple partitions, enabling parallel data processing.
It is like tables in the database.
Partition
A topic divided into multiple partitions for scalability and fault tolerance. Each partition is an ordered, immutable sequence of records that is continually appended to a commit log. Partitions allow Kafka to scale horizontally by distributing data across multiple servers.
Example
Each message within a partition is assigned a unique identifier called an offset. This offset acts as a position marker for the message within the partition.
Offsets are immutable and assigned in a sequential order as messages are produced to a partition.
Consumers use offsets to keep track of their position in a partition. By storing the offset of the last consumed message, consumers can resume reading from the correct position in the event of restart or failure.
Consumers can commit offset automatically at regular intervals or commit manually after processing each message.
Consumers can also start reading from a specific offset based on application needs.
Producer
Producers are clients that publish the messages to Kafka topics. Producers send data to the broker, which then stores it in the appropriate partition of the topic.
Consumer
Consumers are clients that read data from Kafka topics. They subscribe to one or more topics and process the data. Each consumer keeps track of its position in each partition using partition offset.
Consumer Group
A group of consumers work together to consume data from a topic. Each consumer in the group processes data from different partitions, allowing for parallel processing and load balancing.
KRaft
Record
A Kafka record, also known as a message, is a unit of data in Kafka. It consists of
Each partition in a Kafka topic can have multiple replicas, which are distributed across different brokers in the cluster to ensure fault tolerance and high availability.
Leader
Each partition in a Kafka topic has a single leader. The leader is responsible for handling all read and write requests for that partition. This ensures that all data for a partition is processed in a consistent and orderly manner.
Follower

Broker
Kafka operates as a cluster composed of one or more servers, known as brokers. These brokers are responsible for storing data and handling client requests. Each broker has a unique ID and can manage hundreds of thousands of read and write operations per second from thousands of clients.
Topic
A topic is a category where records are stored in the Kafka cluster. Topics are divided into multiple partitions, enabling parallel data processing.
It is like tables in the database.
Partition
A topic divided into multiple partitions for scalability and fault tolerance. Each partition is an ordered, immutable sequence of records that is continually appended to a commit log. Partitions allow Kafka to scale horizontally by distributing data across multiple servers.
Example
- If a topic has 3 partitions and there are 3 brokers, each broker will have one partition.
- If a topic has 3 partitions and there are 5 brokers, the first 3 brokers will each have one partition, while the remaining 2 brokers will not have any partitions for that specific topic.
- If a topic has 3 partitions and there are 2 brokers, each broker will share more than partition which leads to unequal distribution of load.
Each message within a partition is assigned a unique identifier called an offset. This offset acts as a position marker for the message within the partition.
Offsets are immutable and assigned in a sequential order as messages are produced to a partition.
Consumers use offsets to keep track of their position in a partition. By storing the offset of the last consumed message, consumers can resume reading from the correct position in the event of restart or failure.
Consumers can commit offset automatically at regular intervals or commit manually after processing each message.
Consumers can also start reading from a specific offset based on application needs.
Producer
Producers are clients that publish the messages to Kafka topics. Producers send data to the broker, which then stores it in the appropriate partition of the topic.
Consumer
Consumers are clients that read data from Kafka topics. They subscribe to one or more topics and process the data. Each consumer keeps track of its position in each partition using partition offset.
Consumer Group
A group of consumers work together to consume data from a topic. Each consumer in the group processes data from different partitions, allowing for parallel processing and load balancing.
KRaft
It is used to manage and coordinate the brokers, assisting with leader election for partitions, configuration management, and cluster metadata. In older versions of Kafka, ZooKeeper is utilized to perform these tasks.
Record
A Kafka record, also known as a message, is a unit of data in Kafka. It consists of
- Key: It is optional and helps determine the partition for a record. Kafka uses a hashing algorithm to map the key to a specific partition, ensuring all records with the same key go to the same partition, maintaining their order.
- Value: It contains actual data and can by type such as a string, JSON, or binary data, depending on the serialization format used.
- Header: These are optional key-value pairs that can be included with a record. They provide additional metadata about the record
- Timestamp: Each record has a timestamp to indicate when the record was published. This timestamp can be set by the producer or assigned by the Kafka broker when the record is received.
Each partition in a Kafka topic can have multiple replicas, which are distributed across different brokers in the cluster to ensure fault tolerance and high availability.
Leader
Each partition in a Kafka topic has a single leader. The leader is responsible for handling all read and write requests for that partition. This ensures that all data for a partition is processed in a consistent and orderly manner.
Follower
Partitions have one or more followers. The Followers replicate the data from the leader using in-sync replicas (ISR) to ensure strong redundancy and durability.
Apache Kafka offers following five core Java APIs to facilitate cluster and client management.
1. Producer API: It allows applications to write stream of records to one or more Kafka topics.
2. Consumer API: It allows applications to read stream of records Kafka topics.
3. Kafka Streams API: It allows applications to read data from input topics, perform transformations, filtering, and aggregation, and then write the results back to output topics.
4. Kafka Connect API: It is used to develop and run reusable data connectors that pull data from external systems and send it to Kafka topics, or vice versa.
5. Admin API: It is used for managing Kafka clusters, brokers, topics and ACLs
Happy Coding :)
1. Producer API: It allows applications to write stream of records to one or more Kafka topics.
2. Consumer API: It allows applications to read stream of records Kafka topics.
3. Kafka Streams API: It allows applications to read data from input topics, perform transformations, filtering, and aggregation, and then write the results back to output topics.
4. Kafka Connect API: It is used to develop and run reusable data connectors that pull data from external systems and send it to Kafka topics, or vice versa.
5. Admin API: It is used for managing Kafka clusters, brokers, topics and ACLs
Apache Kafka for Developers Journey:
- Apache Kafka for Developers #1: Introduction to Kafka and Comparison with RabbitMQ
- Apache Kafka for Developers #2: Kafka Architecture and Components
- Apache Kafka for Developers #3: Kafka Topic Replication
- Apache Kafka for Developers #4: Kafka Producer and Acknowledgements
- Apache Kafka for Developers #5: Kafka Consumer and Consumer Group
- Apache Kafka for Developers #6: Kafka Consumer Partition Rebalancing
- Apache Kafka for Developers #7: Kafka Consumer Commit Offset
- Apache Kafka for Developers #8: Kafka Consumer Auto Offset Reset
- Apache Kafka for Developers #9: Replacing ZooKeeper with KRaft
- Apache Kafka for Developers #10:Setting Up Kafka Locally with Docker
- Apache Kafka for Developers #11: Creating and Managing Kafka Topics
- Apache Kafka for Developers #12: Setting Up a Kafka Producer in Node.js using KafkaJS
- Apache Kafka for Developers #13: Setting Up a Kafka Consumer in Node.js using KafkaJS
- Apache Kafka for Developers #14: Order Processing with Kafka, Node.js Microservices, and MySQL
Comments
Post a Comment